1.数据分析的流程

提出问题
提出问题,也就是明确需求和目的。
从俊俊的想法中不难发现,我们需要解决两个问题,分别是:
找出影响便利店销量的因素,并给出对应的提升策略。
根据过往经验,俊俊认为可以从以下三个角度出发,分析便利店销售数据,找出影响销量的因素:
销售情况,比如销售额的变化趋势,市场布局;
商品情况,比如商品的结构;
用户情况,比如下单行为。
收集数据
明确目标后,就可以从目标入手,确定需要哪些数据,获得进行分析的数据集。
俊俊的猜想聚焦于销售情况、商品、用户这三个维度,所以可以从这三个维度来收集订单数据。
俊俊从数据库里获取了2018年1月1日到2021年12月30日,这四年内「便利店的销售数据」,包含下单日期、商品类别、销售额等信息。
该数据集是一个CSV文件,存储在”/Users/junjun/store.csv”路径下。
图中展示了该数据集的一小部分,除了标题行外,其他每一行就是一条订单数据。
数据处理和清洗
获取并读取数据集后,在开展进一步分析前,我们还需要对数据的质量进行检查和处理。
也就是先识别并清洗数据集中的脏数据,然后再看是否需要对数据进行处理,比如转换数据类型等操作。
识别并清洗数据的流程是:
识别并处理缺失值
在pandas中,检查缺失值可以通过
info()函数。我们只用关注该函数返回的数据总行数和各列非空数据的数量即可。
观察输出:
这份数据集的总行数为9935;
订单量和销售额这两列的非空数据都小于数据总行数;
说明存在少量缺失值。
由于缺失值数量较少,我们选择直接删除掉包含缺失值的行数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16# 使用import导入pandas模块,简称为pd
import pandas as pd
'''读取文件'''
data = pd.read_csv("/Users/junjun/store.csv")
'''数据的处理与清洗'''
# 1. 1. 识别并处理缺失值
# TODO 使用布尔索引和isnull()函数,将"订单量"的缺失值筛选出,赋值给变量quanNull
quanNull = data[data["订单量"].isnull()]
# TODO 使用drop()函数,将包含所有"订单量"这一列缺失值的行删除
data.drop(index=quanNull.index, inplace=True)
# TODO 使用info()函数,快速浏览数据集
data.info()识别并处理异常值
接下来进行数据清洗的第二步:识别并处理异常值。
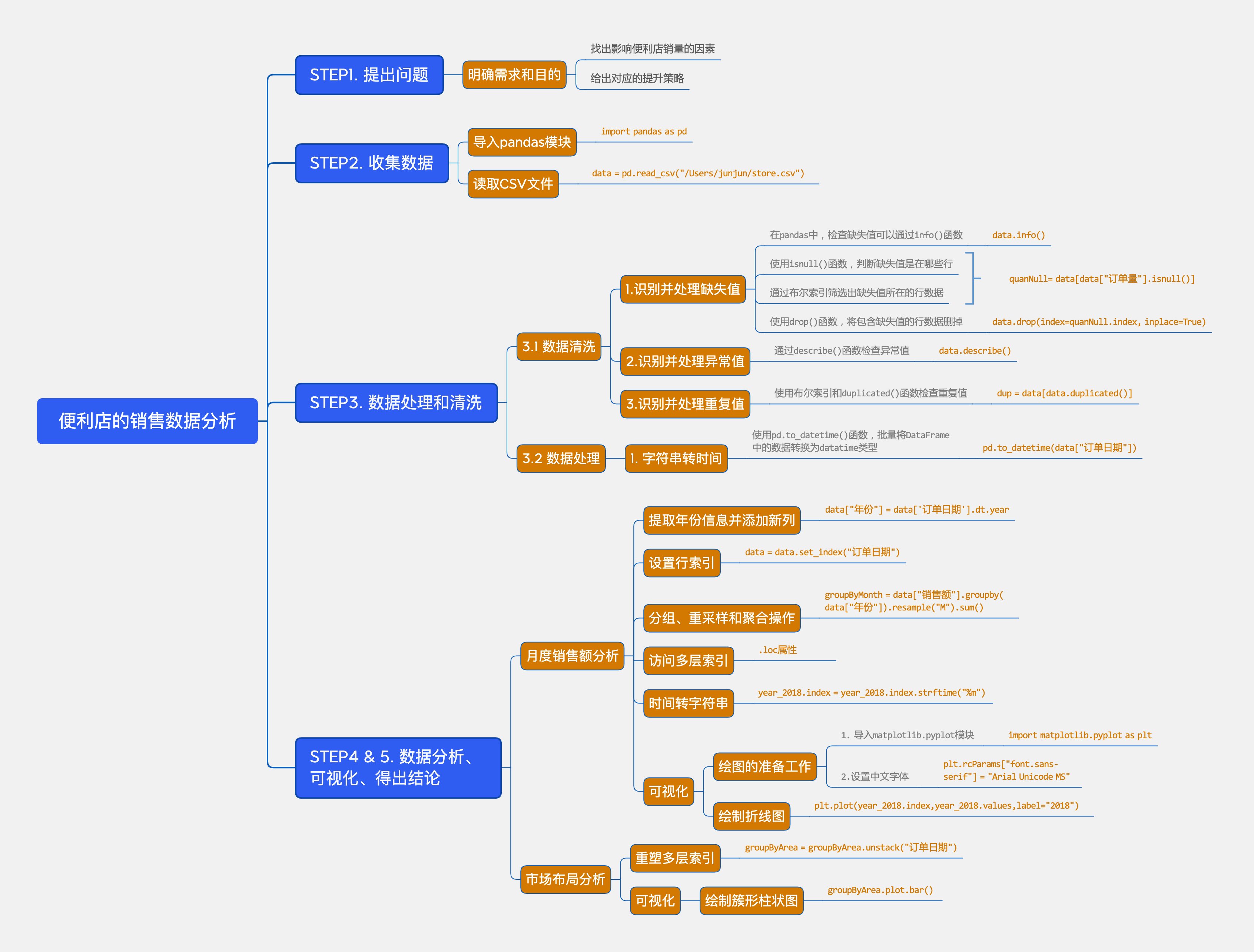
有一个快速识别数据集中是否存在异常值的方法,就是使用描述函数 ——
describe()。输出结果中,很多数字后面都有 e+01、e+09、… 之类的后缀,这是一种科学计数法,代表10的n次方。
现在重点观察下这两列的最小值(min)和最大值(max),我们可以发现以下2个异常情况:
1)订单量的最小值几乎是 0
在实际业务中,不可能出现订单量为 0 的情况。
2)订单量的最大值几乎是 10 的九次方
俊俊的便利店明显无法处理10 个亿的订单量。
这两种数据均属于异常值,会影响分析结果的准确性,所以我们抽取合理范围内的数据,将异常值过滤掉。
处理异常值非常简单,我们只需通过
布尔索引,将订单量这一列值里大于0,以及小于100000000(1.000000e+09)的数据筛选出来,重新赋值给data即可。完成后,再次通过
describe()函数查看筛选后的描述性信息。可以看到,订单量目前的范围在1至2000之间,是一个较合理的订单量范围,不需要再进行数据筛选。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 使用import导入pandas模块,简称为pd
import pandas as pd
'''读取文件'''
data = pd.read_csv("/Users/junjun/store.csv")
'''数据的处理与清洗'''
# 1. 识别并处理缺失值
quanNull= data[data["订单量"].isnull()]
data.drop(index=quanNull.index, inplace=True)
# 2. 识别并处理异常值
# TODO 使用布尔索引筛选出"订单量"这一列值里大于0且小于100000000的数据
data = data[(data["订单量"]>0) & (data["订单量"]<100000000)]
# TODO 查看data的描述性统计信息
print(data.describe())识别并处理重复值
最后,脏数据中还有一种情况,属于重复值。
pandas模块中的
duplicated()函数专门用于判断DataFrame对象中是否存在重复数据。我们可以将布尔索引和该函数结合起来,查看 data 中重复的行。
最后使用print()输出的是一个Empty DataFrame,代表是一个空DataFrame,说明没有重复的行,因此不需要处理。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# 使用import导入pandas模块,简称为pd
import pandas as pd
'''读取文件'''
data = pd.read_csv("/Users/junjun/store.csv")
'''数据的处理与清洗'''
# 1. 识别并处理缺失值
quanNull= data[data["订单量"].isnull()]
data.drop(index=quanNull.index, inplace=True)
# 2. 识别并处理异常值
data = data[(data["订单量"]>0) & (data["订单量"]<100000000)]
# 3. 识别并处理重复值
# 使用布尔索引和duplicated()函数,将data中重复的行筛选出来
dup = data[data.duplicated()]
print(dup)
数据处理
将脏数据清理完毕后,接下来还需要进行数据预处理。
在数据分析基础课中,我们见过最多的处理,就是把数据集里与日期有关的某列数据从字符串转为时间类型。
这是因为存放在CSV文件中的时间大都是字符串类型,不利于后续对其进行时间类型的处理。
字符串转时间
我们可以使用
pd.to_datetime()函数,批量将DataFrame中的数据转换为datatime类型。俊俊获取到的数据集中,只有”订单日期”这一列是需要进行转换的。
我们将这一列转换后的结果输出查看,可以看到已经成功转换为datetime类型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23# 使用import导入pandas模块,简称为pd
import pandas as pd
'''读取文件'''
data = pd.read_csv("/Users/junjun/store.csv")
'''数据的处理与清洗'''
# 1. 识别并处理缺失值
quanNull= data[data["订单量"].isnull()]
data.drop(index=quanNull.index, inplace=True)
# 2. 识别并处理异常值
data = data[(data["订单量"]>0) & (data["订单量"]<100000000)]
# 3. 识别并处理重复值
dup = data[data.duplicated()]
# 4. 数据类型转换
# TODO 使用pd.to_datetime()函数,将"订单日期"列的数据转化为时间格式
data["订单日期"] = pd.to_datetime(data["订单日期"])
# 使用print()输出data["订单日期"]
print(data["订单日期"])
数据分析、可视化、得出结论
数据清洗并处理好后,就可以进入“数据分析”的阶段了。
由于图像能更加凸显数据结果,所以数据分析和可视化往往会同时进行。
接下来,我们就和俊俊一起,从销售、商品和用户这三个角度出发,分析便利店销售数据吧~
分析销售情况
俊俊打算先从销售情况出发,从时间和地区这两个维度,依次分析销售额的变化趋势,及其变化原因。
时间维度,就是便利店每年每月的销售额变化,这会分别帮助俊俊了解不同月份的销售情况,找出是否有淡旺季之分。
地区维度,则是看不同地区销售额的占比,以便对不同区域采取对应的运营策略。
月度销售额分析
我们先来分析便利店每年每月的销售额变化,了解不同月份的销售情况。
找出是否有淡旺季之分和重点销售月份,以便制定经营策略。
为了获取每年的每月销售额,俊俊可以先将便利店销售额按照年份进行分组,再在各个年份的分组中按月重新采样聚合。
相当于是先分组,然后在各个分组里进行重采样,最后聚合。
这个思路和我们在数据分析·基础Day22课学到的非常类似~
可是现在数据中并没有年份信息,所以需要先从”订单日期”里进行提取。
我们可以使用
data["订单日期"].dt.year获取 “订单日期” 这列数据的年份信息,并将其作为新列添加到data中。通过输出可以看到,已在data变量中成功添加了一列年份信息数据。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27# 使用import导入pandas模块,简称为pd
import pandas as pd
'''读取文件'''
data = pd.read_csv("/Users/junjun/store.csv")
'''数据的处理与清洗'''
# 1. 识别并处理缺失值
quanNull= data[data["订单量"].isnull()]
data.drop(index=quanNull.index, inplace=True)
# 2. 识别并处理异常值
data = data[(data["订单量"]>0) & (data["订单量"]<100000000)]
# 3. 识别并处理重复值
dup = data[data.duplicated()]
# 4. 数据类型转换
data["订单日期"] = pd.to_datetime(data["订单日期"])
'''销售情况分析'''
# 1. 分析不同月份销售情况
# 使用data["订单日期"].dt.year获取 "订单日期" 这列数据的年
# 并作为data中的新列
data["年份"] = data['订单日期'].dt.year
# 输出data
print(data)还有一点很重要:重采样需要根据时间格式的行索引来进行操作,否则会出现报错。
因此,为了在处理过程中更加方便,我们通常会把数据中时间格式的列作为行索引index后,再进行重采样。
本例中,我们可以使用
set_index()函数将data[“订单日期”]设置成data变量的行索引index。1
2
3
4
5# 使用set_index()函数,把"订单日期"列设置为index
data = data.set_index("订单日期")
# 输出data
print(data)接下来,就可以对销售额完成分组、重采样和聚合操作。
先对data[“销售额”]使用
groupby()函数,按照data[“年份”]进行分组,这样最后的结果里就只会有销售额,不包含其它无关信息,比如订单量等。再按月(”M”)进行重采样,最后求和。具体代码如下:
1
2
3
4
5
6
7# 使用groupby()、resample()和sum()函数
# 计算每年每个月的销售额总和
# 将结果赋值给变量groupByMonth
groupByMonth = data["销售额"].groupby(data["年份"]).resample("M").sum()
# 输出groupByMonth
print(groupByMonth)获取到2018-2021这四年内每个月的销售额后,俊俊希望能将每年对应的销售额绘制成一个折线图,并将四年的折线图都放在一个画布里来展示。
那我们怎么能通过groupByMonth画出对应的折线图呢?
我们来观察一下groupByMonth,可以看到,现在的销售额按照年份进行了分组,每年都有每月对应的销售额。
并且,出现了两层行索引:
第一层索引是使用groupby()函数时产生的,对应各年份;
第二层索引是使用resample()函数时产生的,对应各月份。

我们可以通过
.loc属性,访问groupByMonth的多层索引,将每年的数据依次提取出来。这样,俊俊就可以依次根据year_2018、year_2019、year_2020和year_2021变量,绘制出对应年份的每月销售额变化趋势。
1
2
3
4
5
6
7
8# 依次提取2018、2019、2020和2021对应的销售额数据
year_2018 = groupByMonth.loc[2018]
year_2019 = groupByMonth.loc[2019]
year_2020 = groupByMonth.loc[2020]
year_2021 = groupByMonth.loc[2021]
# 使用print()输出变量year_2021
print(year_2021)示例中,我们已经做了绘图的准备工作。
为了让图像更利于理解,我们使用
strftime()函数,依次将year_2018、year_2019、year_2020和year_2021的index转换为”月”的格式。然后,就可以依次调用4次
plt.plot()函数绘制折线图,并传入label参数,设置对应的图例。在使用
plt.show()展示图像前,通过plt.legend()方法显示图例即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# 通过给 plt.rcParams["font.sans-serif"] 赋值
# 将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
# 依次将year_2018、year_2019、year_2020和year_2021的index
# 转换为"月"的格式
year_2018.index = year_2018.index.strftime("%m")
year_2019.index = year_2019.index.strftime("%m")
year_2020.index = year_2020.index.strftime("%m")
year_2021.index = year_2021.index.strftime("%m")
# 使用plt.plot()函数
# 以year_2018.index为x轴的值和以year_2018.values为y轴的值
# "2018"作为图例,绘制展现2018年每月销售额的折线图
plt.plot(year_2018.index,year_2018.values,label="2018")
# 使用plt.plot()函数
# 以year_2019.index为x轴的值和以year_2019.values为y轴的值
# "2019"作为图例,绘制展现2019年每月销售额的折线图
plt.plot(year_2019.index,year_2019.values,label="2019")
# 使用plt.plot()函数
# 以year_2020.index为x轴的值和以year_2020.values为y轴的值
# "2020"作为图例,绘制展现2020年每月销售额的折线图
plt.plot(year_2020.index,year_2020.values,label="2020")
# 使用plt.plot()函数
# 以year_2021.index为x轴的值和以year_2021.values为y轴的值
# "2021"作为图例,绘制展现2021年每月销售额的折线图
plt.plot(year_2021.index,year_2021.values,label="2021")
# 使用plt.legend()函数显示图例
plt.legend()
# 使用plt.show()函数显示图像
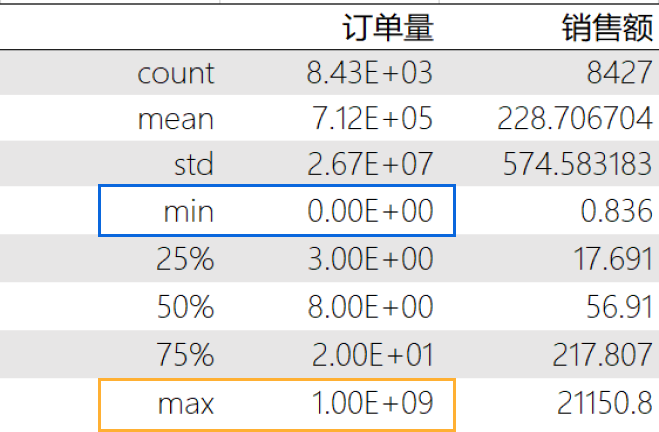
plt.show()通过不同年份月度销售额我们可以看出:
该便利店2018年-2021年每一年的销售额同比上一年都是上升趋势,销售季节性明显,总体上半年是淡季,下半年是旺季。
上半年中5月份销售额比较高,下半年中7月份的销售额偏低。
对于旺季的月份,俊俊可以继续维持运营推广等策略,还可以加大投入,提高整体销售额;而对于淡季的月份,可以结合产品特点进行新产品拓展,举办一些促销活动等吸引客户。
市场布局分析
完成时间维度销售额的分析,接下来,俊俊打算分析市场布局。
他的便利店订单共来自全国6个地区,因此可以看一下不同地区之间的销售情况,以便对不同地区采取对应的经营策略。

俊俊认为可以通过簇形柱状图,来直观展示2018-2021这四年各地区的销售情况。
那么我们就需要获取每个地区的每年销售总额。
按照之前的思路,其实就是先将便利店销售额按照每个地区进行分组,再在各个地区的分组中按年份重新采样聚合。
我们先来尝试获取每个地区的每年销售总额。
和之前一样,需要先使用
set_index()函数将data[“订单日期”]设置成data变量的行索引index。然后,就可以对data[“销售额”]使用
groupby()函数,按照data[“地区”]进行分组。再按年(”Y”)进行重采样,最后求和。具体代码如下:
1
2
3
4
5
6
7# 使用groupby()、resample()和sum()函数
# 计算每个地区每年的销售额总和
# 将结果赋值给变量groupByArea
groupByArea =data["销售额"].groupby(data['地区']).resample("Y").sum()
# 输出groupByArea
print(groupByArea)现在我们又得到了一个包含双层索引的DataFrame。
接下来就可以根据这个groupByArea,绘制簇形柱状图。
俊俊希望簇形柱状图的x轴是地区,y轴数据则是各地区对应的每年销售额。
.png)
绘制簇形柱状图只需要对一个DataFrame对象,使用pandas模块中的
plot.bar()函数即可。在不指定x轴和y轴数据的情况下,行索引index会作为x轴,每一行数值类型的值会被分组到并排的柱子中作为y轴。
也就是说,如果要绘制出俊俊所设想的簇形柱状图,需要重塑groupByArea的多层索引,让地区作为行索引index,各地区每年的销售总额作为每一行数值类型的值。
我们可以使用
unstack()函数,将groupByArea里,名称为”订单日期”的行索引转变为列索引即可。转变后,groupByArea的行索引就变成了地区,列索引则变成了订单日期。
1
2
3
4
5# 使用unstack()函数将groupByArea按照"订单日期"重新排列
groupByArea = groupByArea.unstack("订单日期")
# 输出groupByArea
print(groupByArea)现在就可以根据groupByArea,绘制簇形柱状图。绘图的准备工作已做好~
老规矩,为了让图像更利于理解,我们使用
strftime()函数,先将groupByArea的columns转换为”年”的格式。然后直接对groupByArea调用
plot.bar()函数即可。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 导入matplotlib.pyplot,并使用"plt"作为该模块的简写
import matplotlib.pyplot as plt
# 通过给 plt.rcParams["font.sans-serif"] 赋值
# 将字体设置为 Arial Unicode MS
plt.rcParams["font.sans-serif"] = "Arial Unicode MS"
# TODO 将groupByArea变量中columns转换为"%Y"的格式
groupByArea.columns = groupByArea.columns.strftime("%Y")
# TODO 对groupByArea变量使用plot.bar()函数绘制簇形柱状图
groupByArea.plot.bar()
# 使用plt.show()函数显示图像
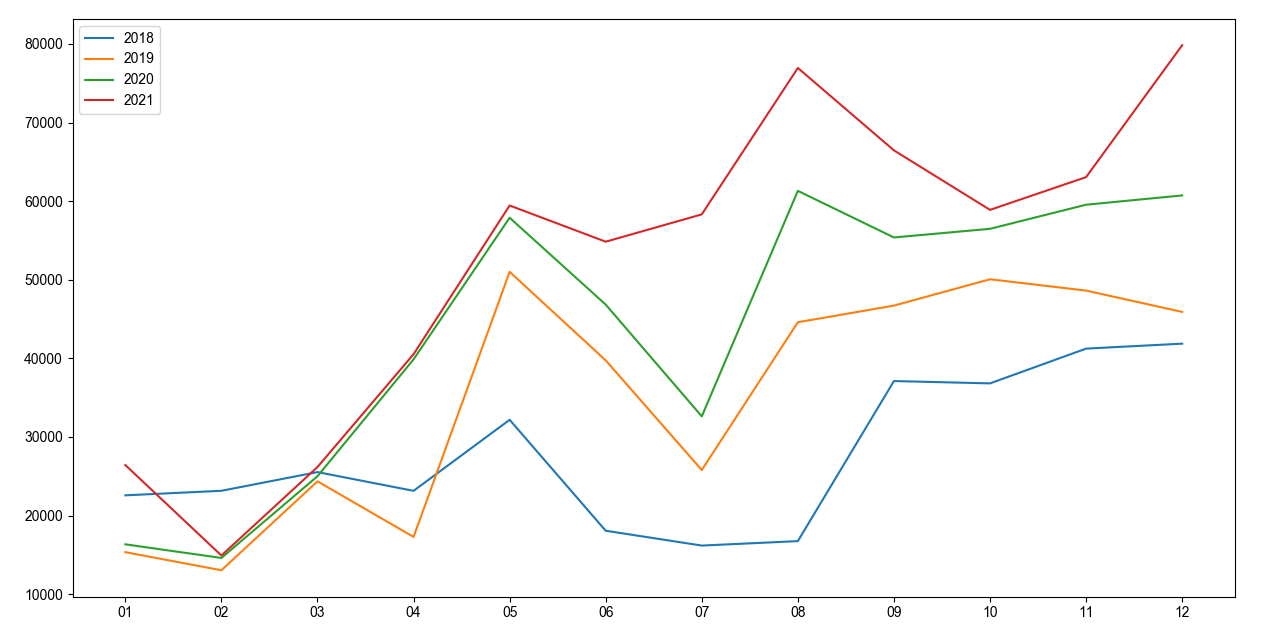
plt.show()通过不同地区年度销售额我们可以看出:
每个地区总体每年销售额均处于上升趋势,尤其在东北、中南和华东三个地区的增长速度较快,可以看出市场占有能力在不断增加,企业市场前景比较好,下一年可以适当加大运营成本。
其他地区可以根据自身地区消费特点,借鉴东北、中南和华东地区的运营模式。