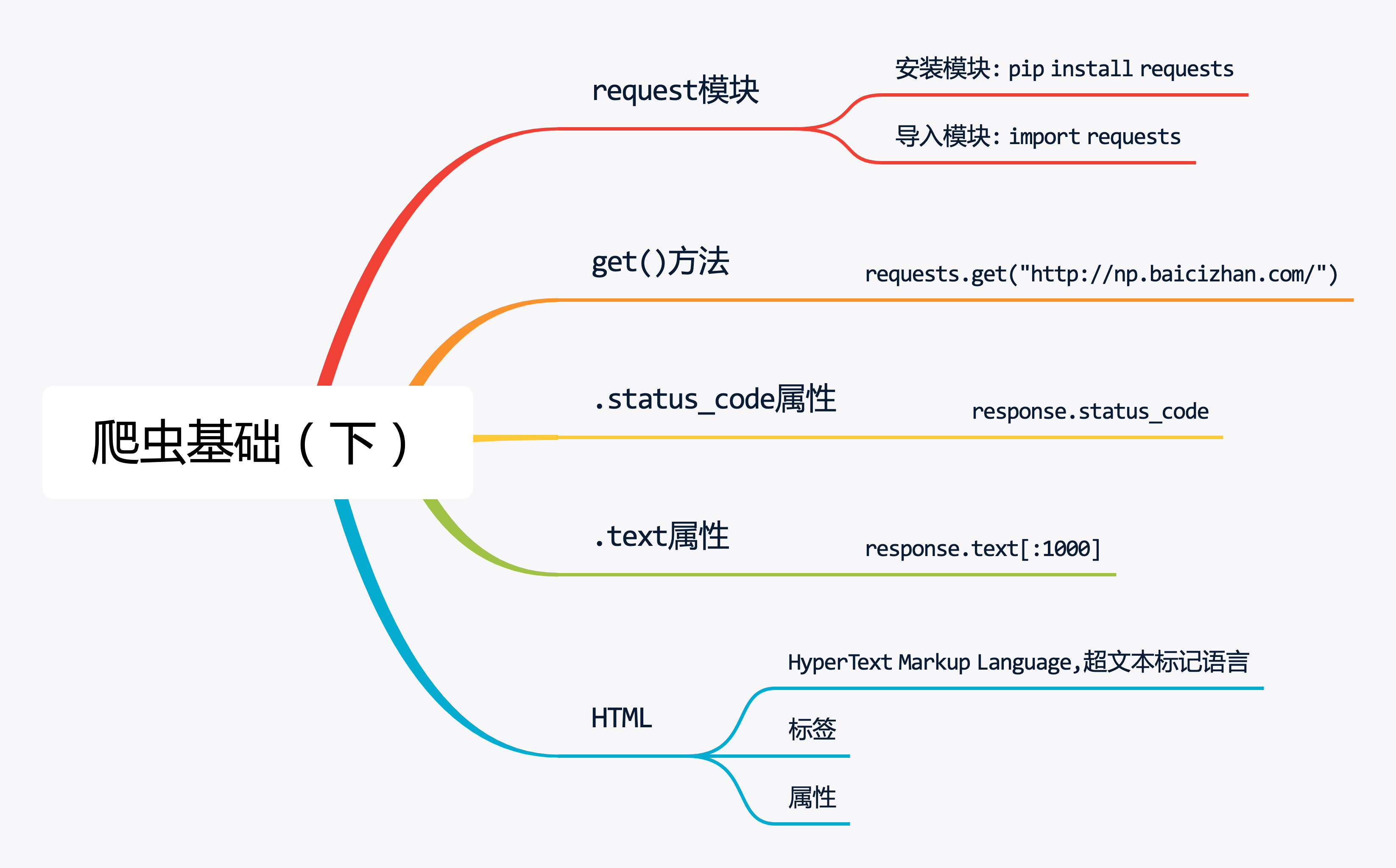
1.requests模块的安装与导入
前面内容讲到,网页爬虫能够获取网页上的信息,要使用Python来爬取网页内容,需要安装requests模块,该模块可以用于获取网络数据。
由于requests模块是Python的第三方模块,需要额外安装,安装requests模块非常简单,在电脑终端输入代码:pip install requests
前面介绍了URL结构。
那么对于爬虫来说,要获取下图网页中的内容,就需要网页的URL。
复制链接的方法如下图所示,打开网页,点击链接框,右键选择复制。
https://nocturne-spider.baicizhan.com/2020/07/29/example-post-3/
2.请求网页内容
requests.get()函数可用于模拟浏览器请求网页的过程,在Python语言中使用该函数,就能够获取网页数据。
get()函数中传入要访问网页的URL,就像浏览器打开URL一样。
例如,获取夜曲编程首页的链接就要写:
requests.get(“https://np.baicizhan.com/")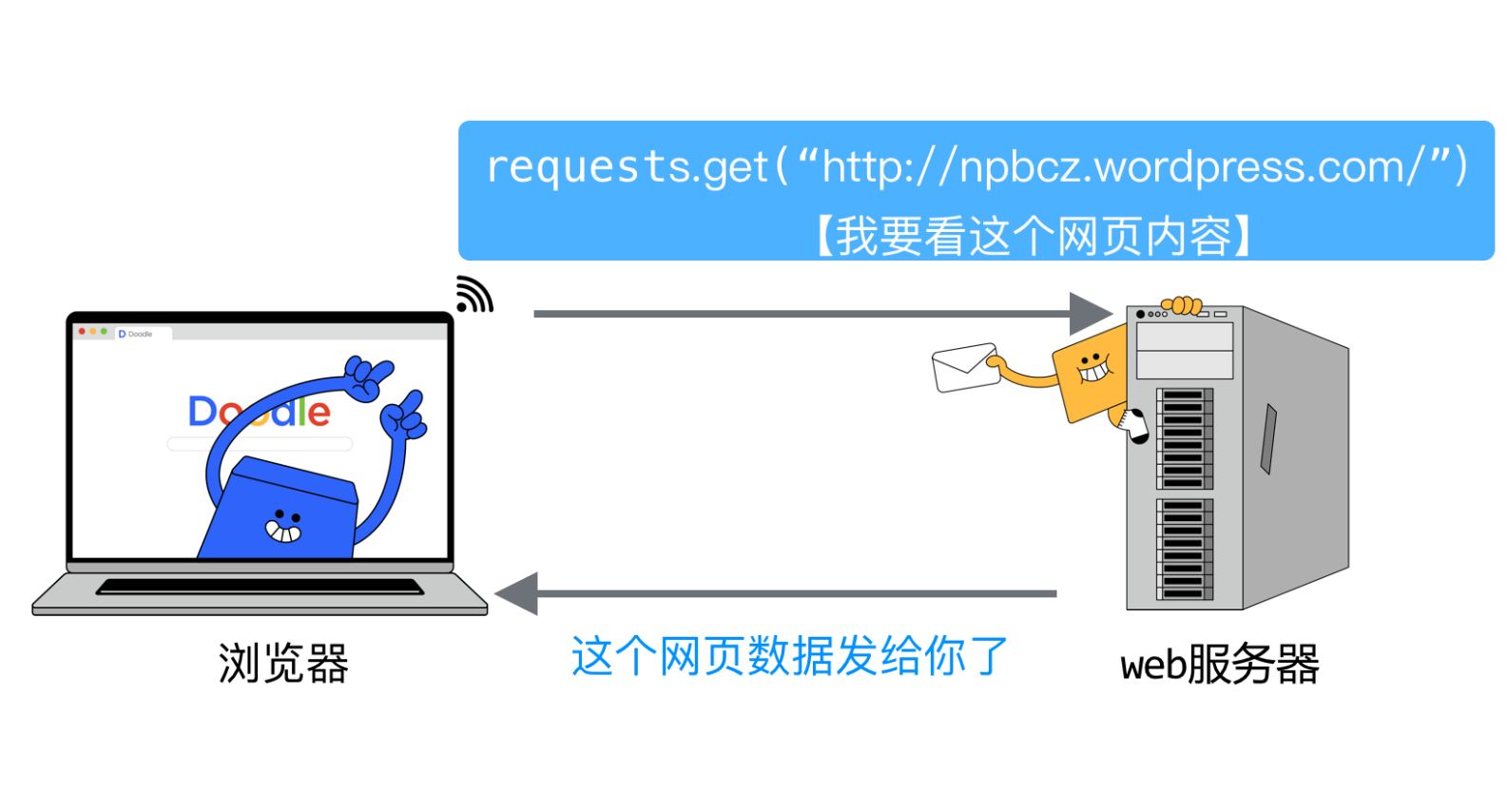
requests.get()是获取网页信息的主要函数,使用该函数获取案例网页的URL,会返回一个Response对象,也就是前面说到的响应消息。使用
print输出响应消息会得到Response [200]表示响应消息中状态码为200,说明此次浏览器的请求执行成功。这里使用
requests.get()方法获取案例URL网页数据,并输出返回内容。前面提到requests.get()函数是模拟浏览器请求网页的过程,那么,怎样查看浏览器中的请求方法呢?
复制的链接为https://nocturne-spider.baicizhan.com/2020/07/29/example-post-3/,总结上述步骤。
关于浏览器,我们推荐使用Chrome浏览器。
刚刚的操作步骤需要我们掌握,(现在看到的网页结构看起来确实有点复杂)。
但是,不要着急,在后续的课程学习和项目练习中,你将逐渐熟悉并掌握网页结构。

在浏览器中查看Response Headers中的信息就能够找到status:200,状态码200代表此次请求执行成功。
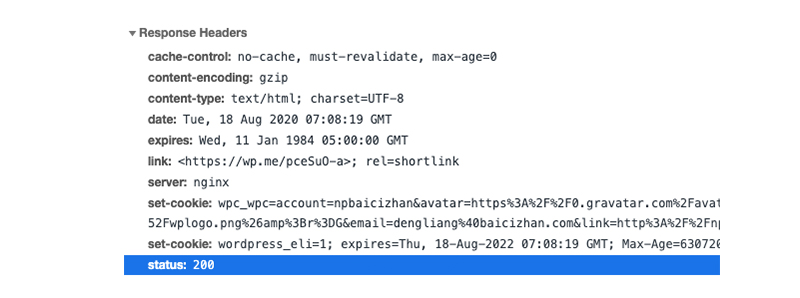
使用.status_code属性就可以查看状态码,这里输出的状态码数据类型是整型哦。
1
2
3
4
5
6
7
8
9
10
11
12
13
14# 使用import导入requests模块
import requests
# 将网页链接赋值给url
url = "https://nocturne-spider.baicizhan.com/2020/07/29/example-post-3/"
# 使用requests.get()方法获取url的内容,将结果赋值给response
response = requests.get(url)
# 使用.status_code属性获取状态码,并赋值给statusCode
statusCode = response.status_code
# 输出statusCode
print(statusCode)在前面的课程中学到状态码代表服务器执行的结果,状态码种类多样。
例如:下面代码中的URL是错误的,当使用requests.get()请求URL时,就会返回404,404(Not Found)表示服务器无法找到请求的资源。
而只有状态码返回为200时,才能够成功获取到网页内容。
为满足上面的运行逻辑,我们要使用条件判断语句if..else先判断状态码,当状态码等于200时,再进行下一步操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 使用import导入requests模块
import requests
# 将网页链接赋值给url
url = "https://nocturne-spider.baicizhan.com/2020/07/29/example-post-3/"
# 使用requests.get()方法获取url的内容,将结果赋值给response
response = requests.get(url)
# TODO 使用if语句判断.status_code属性获取的状态码等于200时
if response.status_code == 200:
# TODO 输出response.status_code
print(response.status_code)
# TODO 不满足条件时
else:
# TODO 输出:请求数据失败
print("请求数据失败")
3.获取网页内容
通过请求URL,已经获取到了Web服务器返回的信息,那这些信息怎样才能呈现出来呢?
这里就要用到.text属性,该属性能够将获取到的网页信息提取出来。
由于网页内容较多,我们这里可以用切片的方法,先输出前1000个字符。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20# 使用import导入requests模块
import requests
# 将网页链接赋值给url
url = "https://nocturne-spider.baicizhan.com/2020/07/29/example-post-3/"
# 使用requests.get()方法获取url的内容,将结果赋值给response
response = requests.get(url)
# 使用if语句判断.status_code属性获取的状态码等于200时
if response.status_code == 200:
# 使用.text属性获取网页前1000个字符的内容,并赋值给content
content = response.text[:1000]
# 输出content
print(content)
# 不满足if的条件时
else:
# 输出 请求数据失败
print("请求数据失败")仔细观察刚刚输出的内容,不像我们日常接触的Python语言。
这是HTML语言,全称为HyperText Markup Language,超文本标记语言,它用来定义网页内容和结构。
HTML是由一系列的标签组成,这些标签组合起来就是我们浏览器看到的网页。

接下来会讲解HTML的标签和属性,后面课程会根据标签和属性去查找文本内容,HTML知识点我们了解即可。
对照观察下图内容和右侧代码。
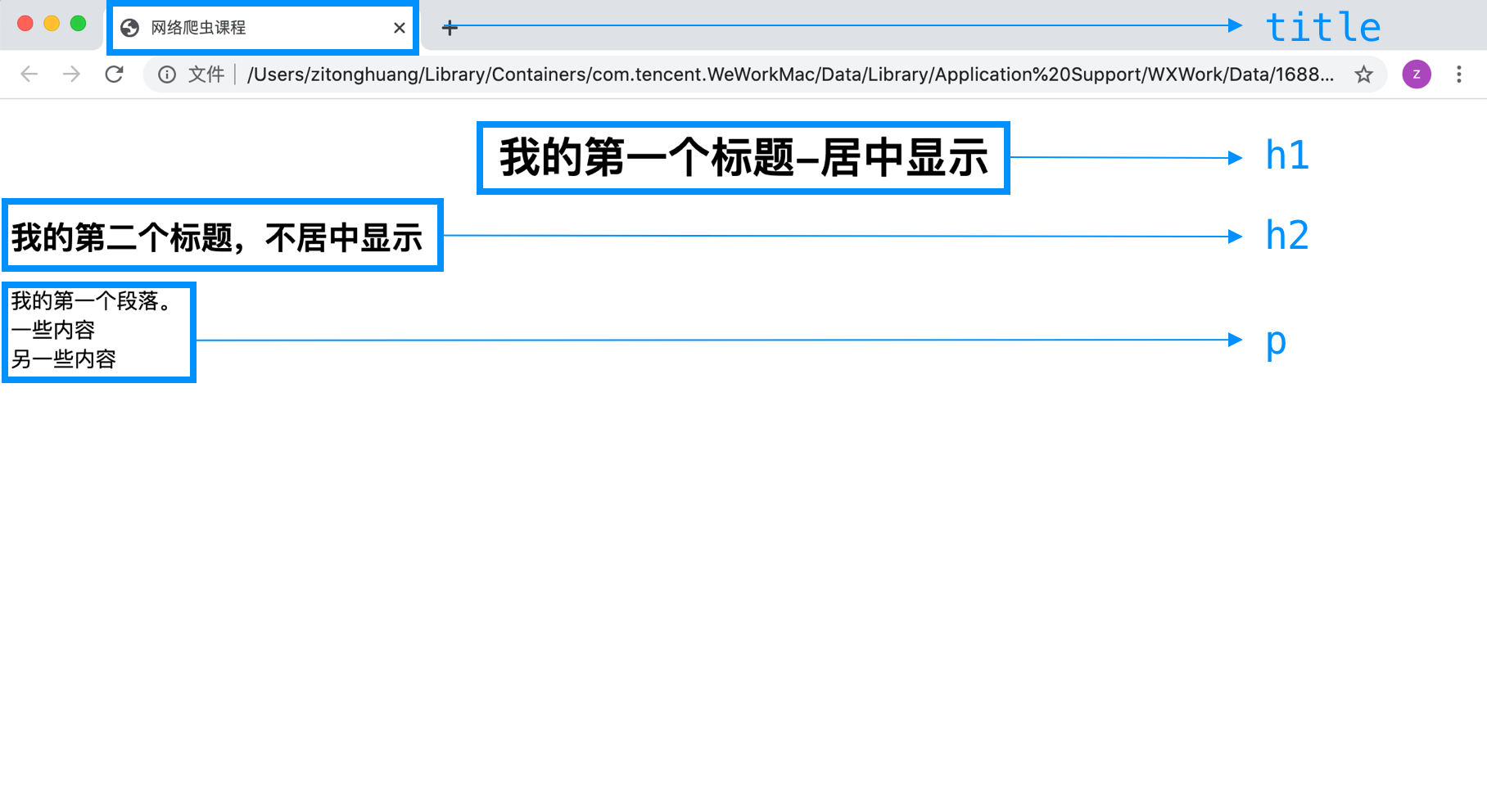
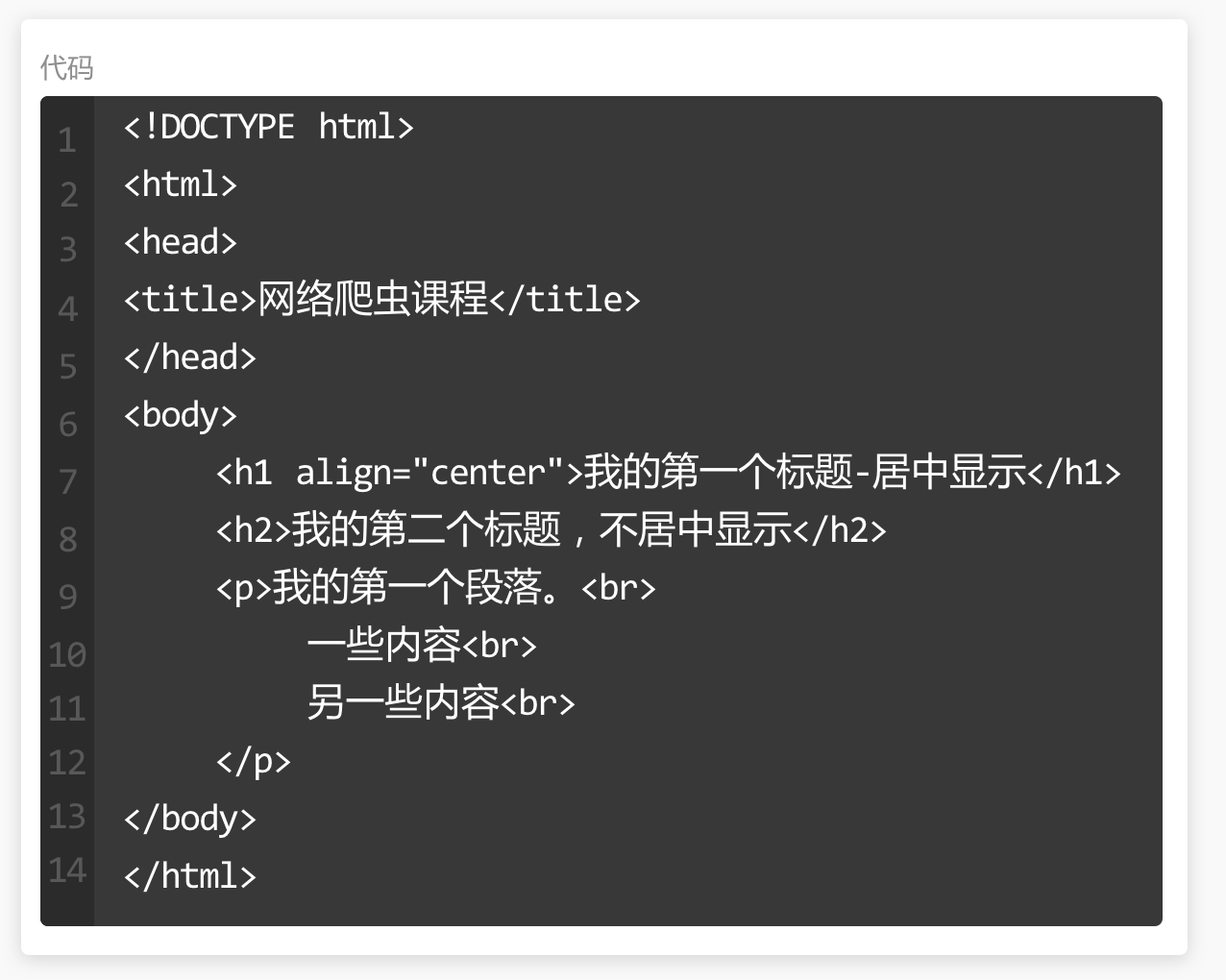
标签:是用来标记内容块的,主要有两种形式成对出现和单独出现。
成对出现的标签
<开始标签>内容<结束标签>
结束标签只比开始标签多一个斜杠”/“。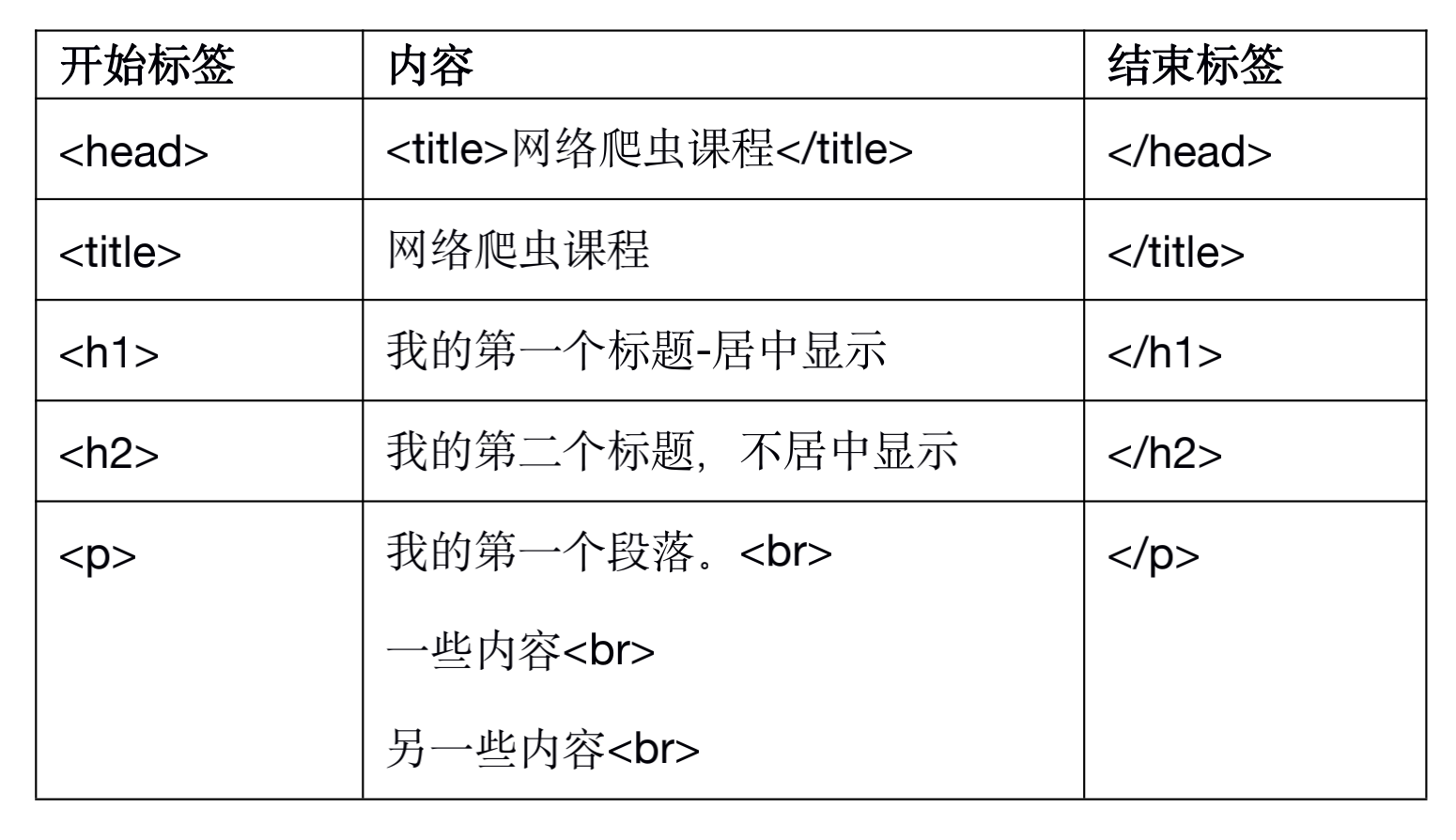
1. <html></html>表明这是一个网页文档。 2. <head></head>标签用于定义文档的头部信息,这些信息不会展示在网页中。 3. <body></body>标签用于定义文档的主体,包含网页的图片、文字、链接、视频等多种展现形式。第9、10、11行的<br>就是单独出现的标签,表示换行。 标签是可以嵌套的,例如<head>元素中嵌套了<title></title>成对标签。 在<body>元素中嵌套了多个成对标签和单独标签。1
2
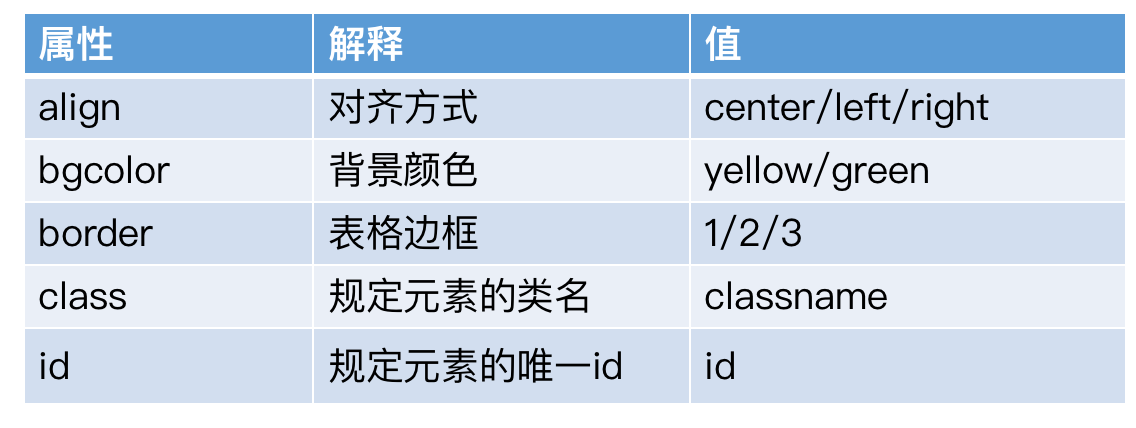
3. 单独标签属性:用于丰富表现形式,一般放在开始标签里,并且以属性名=”属性值”的形式展现。
例如:第7行<h1>标签中,align="center",这里center属性值的作用就是让h1标签的内容居中。属性还可以描述内容的颜色、边框等等。
 右侧的内容,就是前面用.text属性获取到的网页源代码。
右侧的内容,就是前面用.text属性获取到的网页源代码。
到这里我们就完成了网页爬虫基础内容的学习。再来思考课前要回答的问题:
- 爬虫的原理是什么
- 从哪里爬取网页内容
- 爬到的内容长什么
4.总结
HTML是构成网页的标记语言。
URL指定了要访问文档的具体地址。
HTTP协议规定了文档的传递方式。
爬虫就是根据URL,通过HTTP协议去获取HTML内容。