前言
本脚本适用于www.e360xs.com中的专栏小说下载,主要针对的是知乎盐选小说。如用于其他网站,没有啥用。
1. 安装环境
首先安装好python环境(python3系列版本,推荐3.8)
根据不同的系统可以在网上搜索python教程,很快就可以安装好,安装好后在终端运行命令
1
python
如果看到有python的版本显示,则说明安装成功,如果显示错误可能是没有配置好路径

安装requests模块
在终端页面,运行命令
1
pip install requests
安装bs4模块
在终端页面,运行命令
1
pip install bs4 -i https://mirrors.aliyun.com/pypi/simple/
安装lxml模块
在终端页面,运行命令
1
pip install lxml -i https://mirrors.aliyun.com/pypi/simple/
2. 执行脚本
安装好python环境以及所需模块之后,下载脚本,然后来到脚本文件所在的文件夹(你下载到哪里就是哪里),以我的电脑为例,脚本文件所在文件夹为
1 | /Users/vyacheslavkorotki/PycharmProjects/webCrawler/src/webcrawler |
脚本文件名为:select_column.py
在当前文件夹中打开终端(具体操作可以搜索:如何在当前文件夹中打开终端(windows/macos))
在终端运行命令
1 | python select_column.py -u https://www.e360xs.com/mulu/229/229112.html |
-u代表指定网络地址,即后面一串网络地址是可以更改的,根据你所要爬虫的具体专栏定义
比如我要爬取专栏“黑镜规则怪谈”,则其在360小说网对应的网页地址为
1 | https://www.e360xs.com/mulu/229/229112.html |
那么把 -u 后面一串字符修改成对应的网页地址即可,回车键运行命令后可以看到
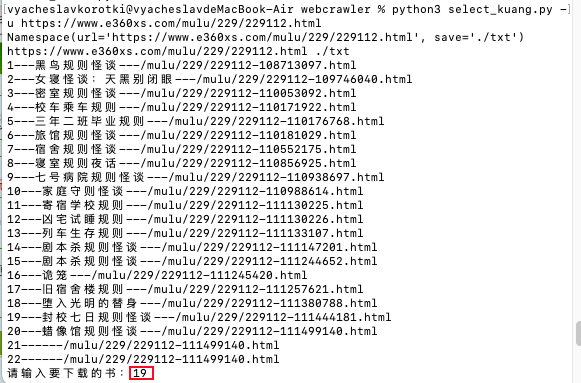
输入想要下载书籍对应的序列号,下载完成后,会有下载成功的提示,对应书籍会默认保存在当前文件夹下面的txt文件夹中(可以使用-s参数进行更改)