1.三个思考题
- 爬虫原理是什么
- 从哪里爬取网页内容
- 爬到的内容长什么样
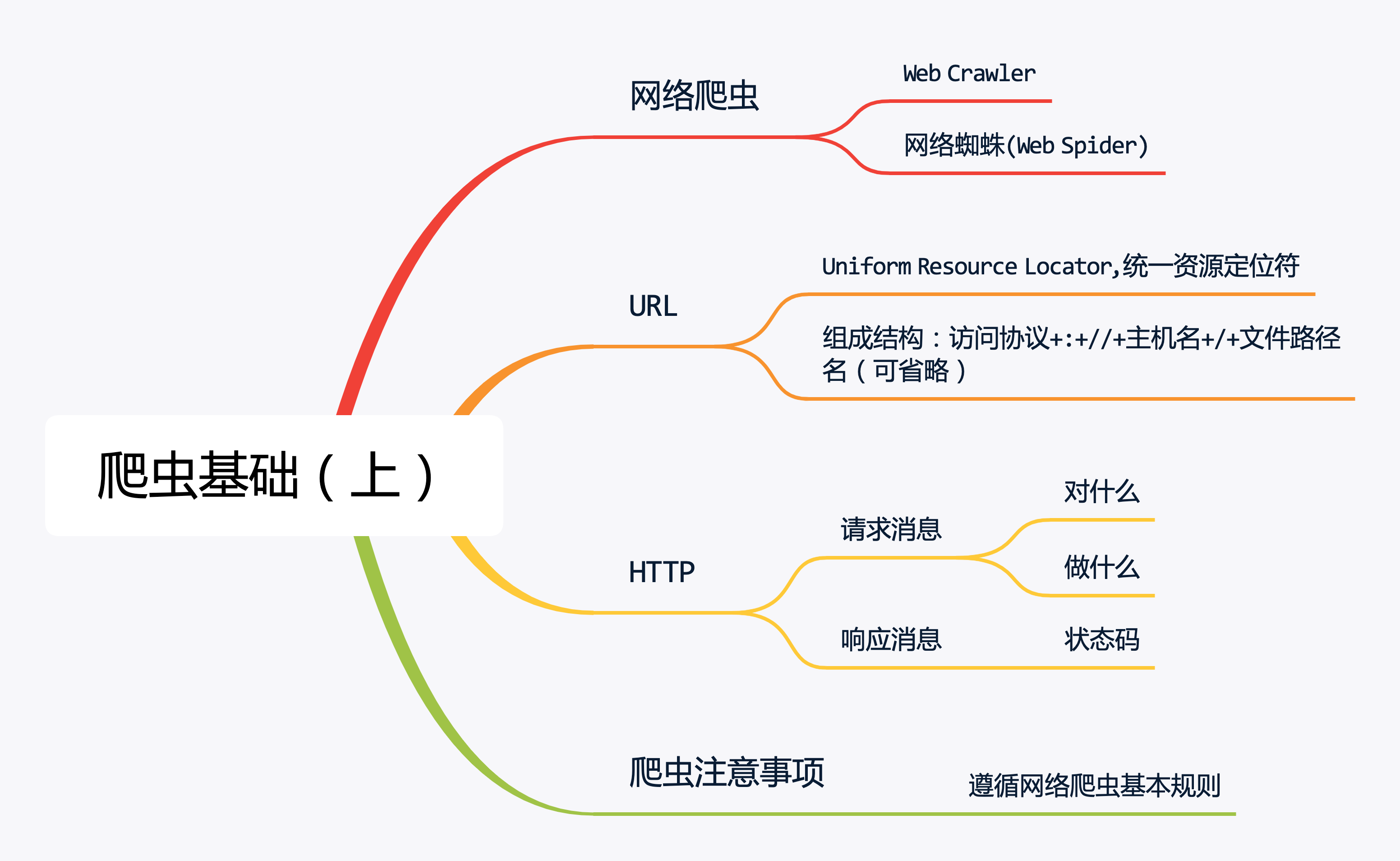
2.爬虫介绍
2.1 概念
网络爬虫英文是 Web Crawler,网络爬虫是按照一定规则自动抓取网页信息的程序。
如果把互联网比作一张大网,把蜘蛛网的节点比作一个个网页。
那么爬虫就是在网页上爬行的蜘蛛,每爬到一个节点就能够访问该网页的信息,所以又称为网络蜘蛛(Web Spider)。
2.2 爬虫获取的数据样式
日常浏览的网页中,既有图片、文字,还有精致的排版,这些页面是怎样展示出来的呢?
其实,这都依靠源代码的功劳,源代码会定义每个标题、段落、图片等排版,浏览器通过解析源代码,呈现出网页画面。
所以,爬虫获取的就是浏览器解析之前的源代码,也就是图中框选的内容。
2.3 爬虫能做的事情
例如,阿岩想要通过某宝评论信息分析出《榴莲味口香糖》值不值得买,首先会打开网页,然后找到评论信息,再一条一条的翻看。
那么对于网络爬虫来说,它能够自动化获取《榴莲味口香糖》网页的所有信息,通过提取网页中的评论内容,将信息保存到文档中,便于对数据进行查看和分析。
所以,网络爬虫就是自动化从网页上获取信息、提取信息和保存信息的过程。
3.URL
定义
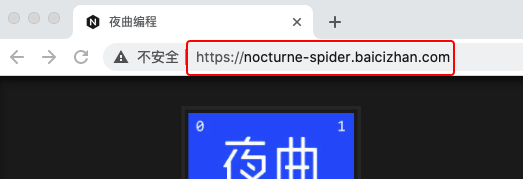
URL全称为Uniform Resource Locator,即统一资源定位符,指定了我们要查找资源的地址。仔细观察右侧两个URL的相同点和不同点。

可以看出两个URL的区别:
相同点:
开头部分都是http://,结尾都是“/”。
不同点:
百词斩链接的中间部分是www.baicizhan.com
夜曲链接的中间部分是np.baicizhan.com
主机名
上面提到的不同点就是主机名(hostname),主机名就是我们要访问的计算机的名字。
np.baicizhan.com是夜曲首页URL中的主机名。www.baicizhan.com是百词斩首页URL中的主机名。
所以,两个URL中主机名不同,访问的网页也不同。我们访问的网页资源是存储在服务器中的。
服务器可用于管理资源并为用户提供服务,其特点就是运算速度快,能为大量用户服务。
服务器的种类有很多,当浏览网页时其主要作用就是将网页信息提供给浏览器,此时的服务器也被称为Web服务器。
HTTP协议
HyperText Transfer Protocol,简称http,超文本传输协议。
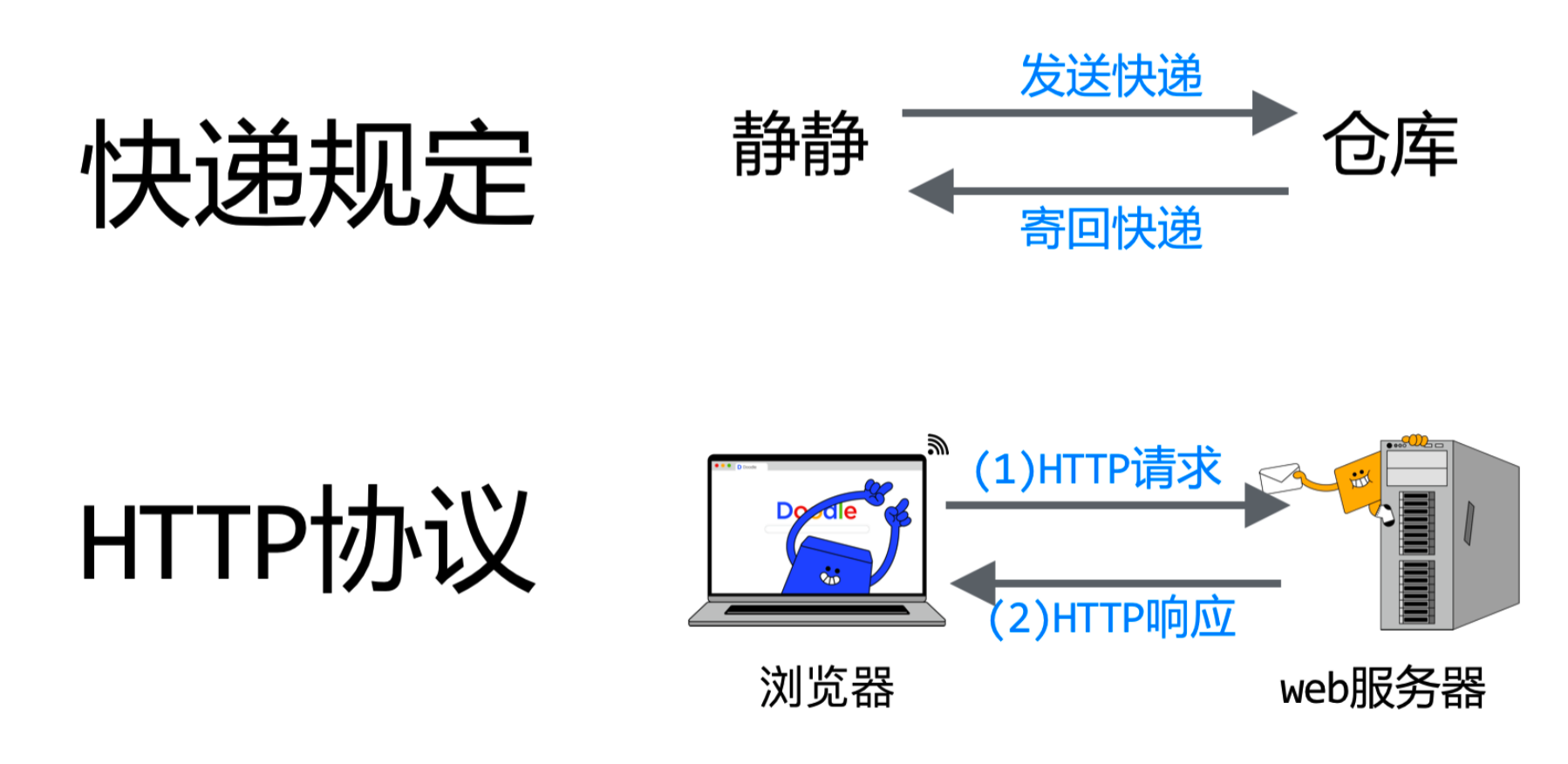
HTTP协议是互联网数据传输的一种规则,它规定了数据的传输方式。
就像是我们寄快递选择的快递公司,快递公司规定了邮寄方式。
HTTP协议定义了客户端和服务器之间传递消息的内容和步骤。
就像快递公司,定义了客户和仓库之间发送快递的内容和步骤。
当URL的协议部分写的是http时,表明服务器传输数据使用的是HTTP协议。
HTTPS协议
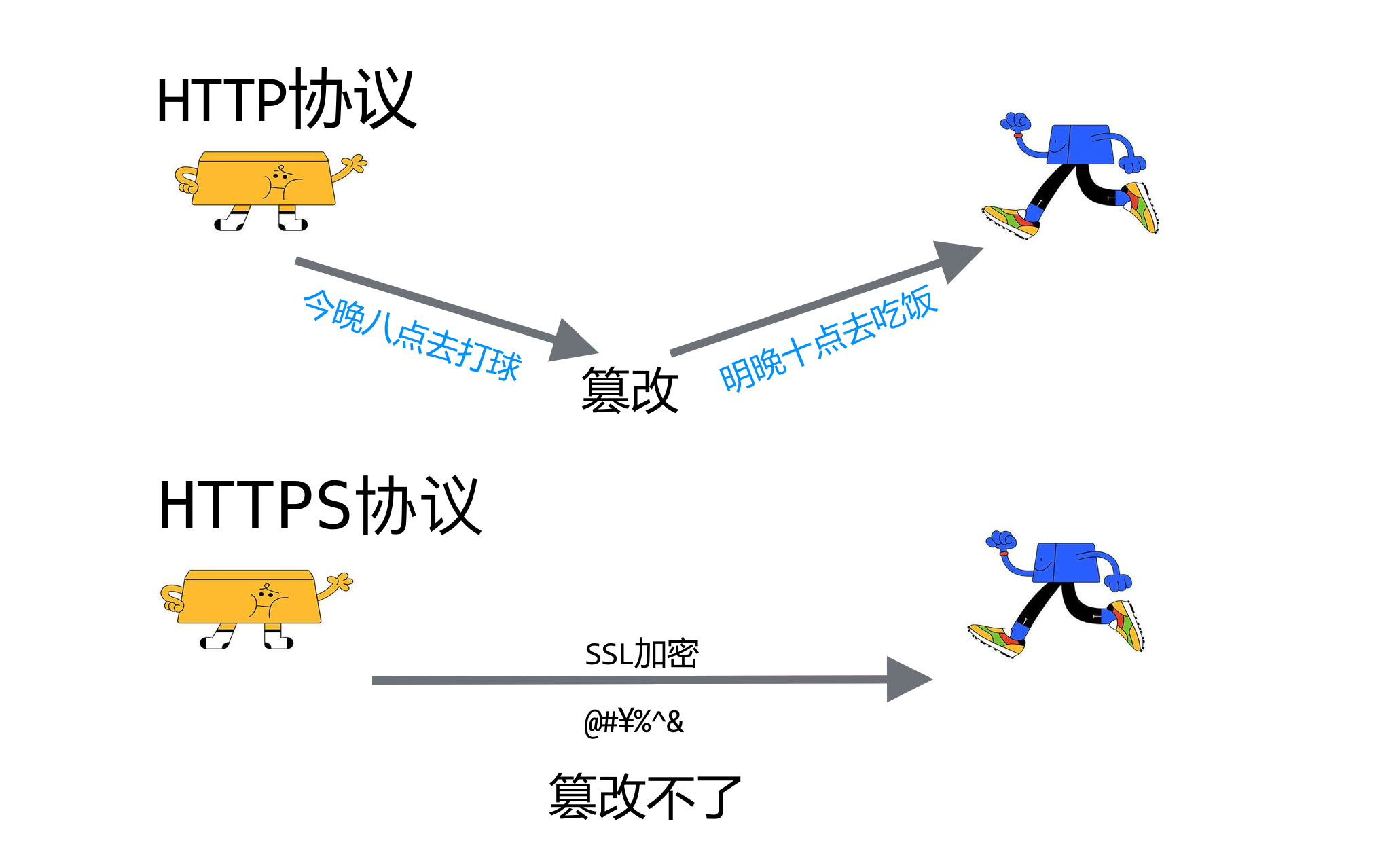
仔细观察日常访问的网页,会发现多数网页URL用的是https,那么http和https有什么区别呢?
HTTPS:HyperText Transfer Protocol Secure,超文本传输安全协议。
HTTP协议在进行数据传输时,内容是未加密的,传输内容可能被窃听或篡改,安全性比较差。
HTTPS并非是全新的协议,只是在传输之前加了一层保护,让内容安全不易被窃听。
所以说,HTTPS协议是HTTP的安全版,使用HTTPS传输能够让传输的数据更安全。
“//”和“/”
“//”为分隔符,表示后面的字符串是主机名。
主机名后面的“/”表明,要在后面写上文件地址,如果不写一般默认为主页。

主机名后面的“/”可以直接加文件路径名称。
而这里的文件名称是可省略的,省略了默认是首页,不省略的会根据文件路径名链接到对应页面。
我们打开一个网页,“/”后面的名称不同,链接到的页面也就不同
总结
- HTTP的作用与快递公司类似
- 主机名是计算机的名字
- 服务器用于管理资源的
- 文件路径能够指定访问资源的具体地址

URL的数据类型是字符串 ,现在使用字符串拼接方式,利用以下几部分拼接出URL。
1.访问协议:http
2.主机名:nocturne-spider.baicizhan.com
3.文件路径:2020/07/29/example-post-3/1
2
3
4
5
6
7
8
9
10
11
12
13
14# 将字符串"http://"赋值给protocol
protocol = "http://"
# 将字符串"nocturne-spider.baicizhan.com"赋值给hostname
hostname = "nocturne-spider.baicizhan.com"
# 将字符串"/2020/07/29/example-post/"赋值给filePath
filePath = "/2020/07/29/example-post-3/"
# 使用加号(+)按顺序连接字符串,赋值给url
url = protocol + hostname + filePath
# 使用print输出url
print(url)
4.请求和响应
案例
学习请求和响应之前,先了解静静换货案例:静静在网上买了一件商品,发现尺码不合适,要换货。这时:
1.【静静】会先寄快递,并填写商品信息和操作(换/退货)。
2.【仓库】收到商品后,就会按照请求去执行,例如:核对客户信息,核对商品等。
3.【仓库】处理完成之后,再将商品通过快递发给静静。
4.【静静】收到商品后,会打开包裹检查验收。
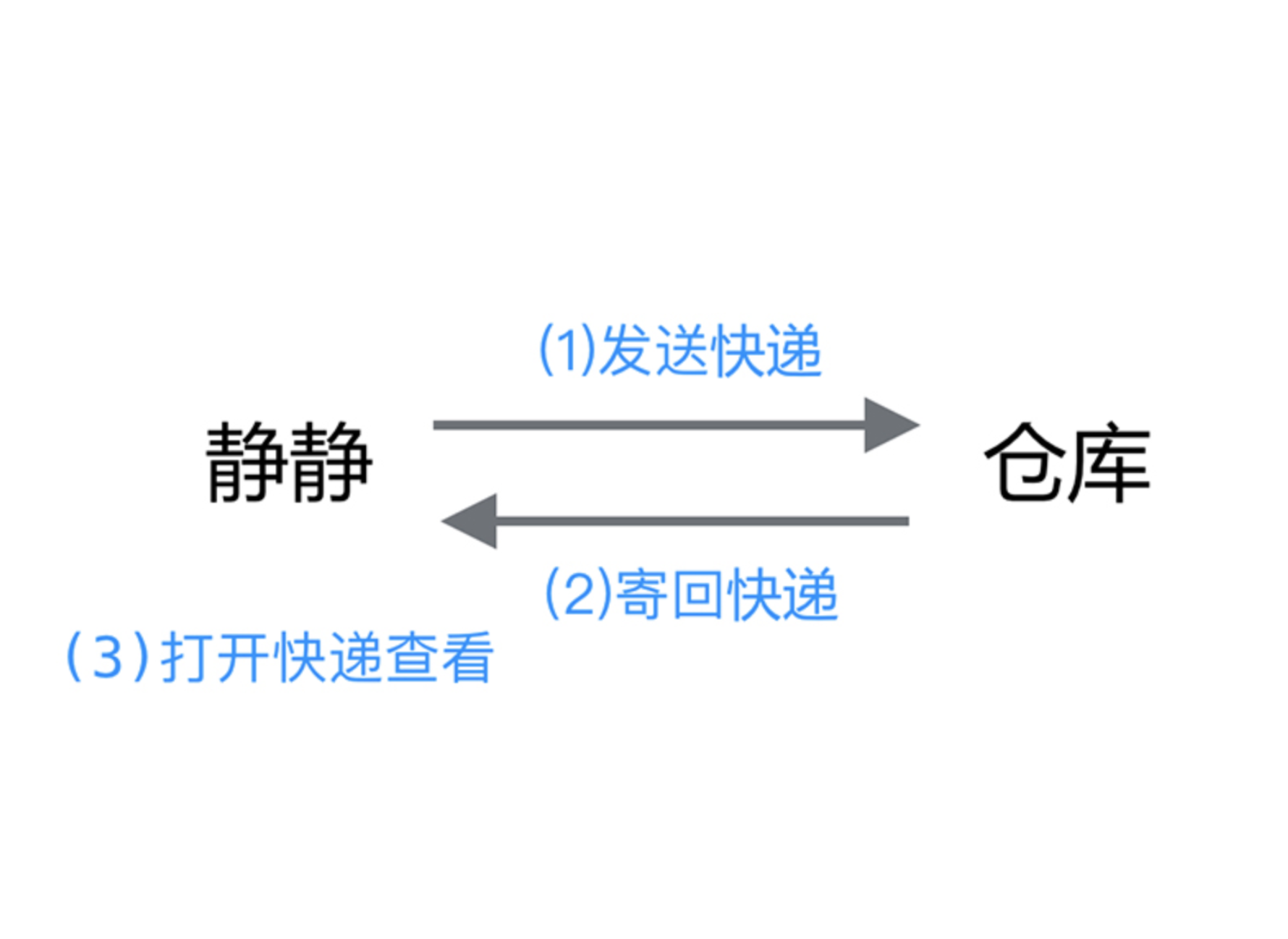
静静换货的案例与HTTP协议类似。
HTTP协议规定了浏览器和服务器之间传递消息的内容和步骤。
我们要从网页中获取源代码,那么就要先了解消息传递的方式。
接下来,学习HTTP协议,消息请求和消息响应方式。
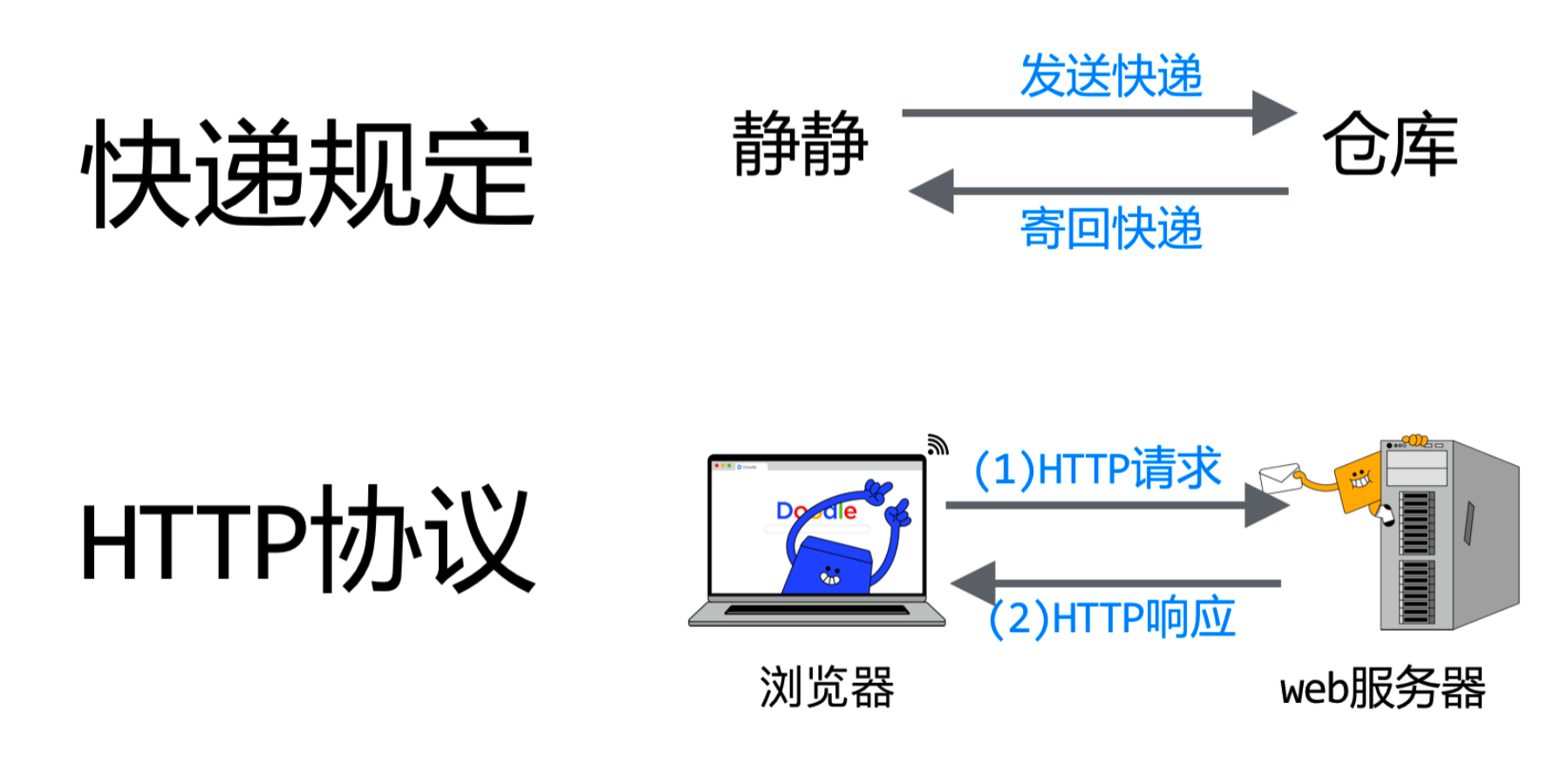
在静静的案例中:
- 【静静】购买商品换货时,先发送快递给仓库,告诉仓库要换的商品和尺码。
- 【仓库】收到快递后,会校验客户信息和商品信息,再通过快递公司将商品寄给静静。
- 【静静】收到商品后,打开包裹查看商品。
HTTP协议:
【浏览器】会先发送HTTP请求,告诉Web服务器需要的数据。
【Web服务器】收到请求后,按照请求执行,并返回HTTP响应消息。
【浏览器】收到返回的数据后,会将源代码解析成网页展示出来。
静静在进行商品换货时,仓库要求先说明“对什么”和“怎么做”。
对什么:是指对哪一件商品进行操作。
怎么做:告诉仓库进行换货还是退货等操作。
HTTP发送的请求(Request)消息主要包含两部分“对什么”和“怎么做”。
“对什么”是我们前面学习的URL,就是要访问的目标。
“怎么做”一般叫做方法,是指让Web服务器完成什么工作。
由于浏览器发送请求时,将“对什么”和“做什么”信息放在头部。所以,存放这些信息的地方又叫请求头(Request Headers)。
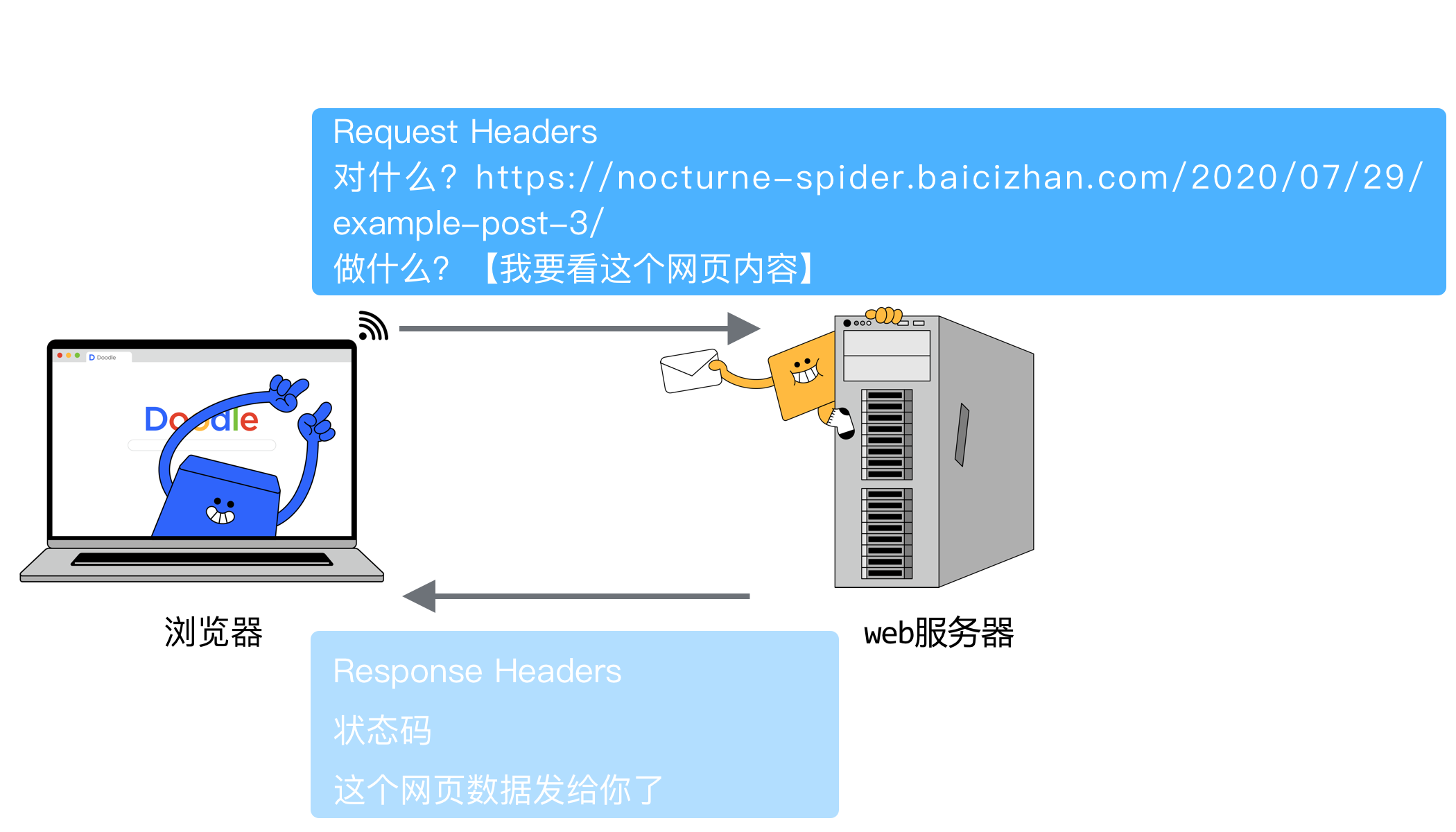
静静的案例中,仓库收到请求后,会根据静静的请求执行操作,并将商品快递发送给客户。
在HTTP协议中:Web服务器收到请求消息后,会根据请求进行处理。并将响应(Response)消息返回给浏览器。
响应消息的头部叫做响应头(Response Headers),响应头中的数据用于告诉浏览器此次请求执行失败还是成功。
5.状态码
定义
响应头(Response Headers)中用于告知浏览器执行结果成功或失败的叫做状态码。
状态码是由3位的数字构成的,主要用于告知客户端的HTTP请求的执行结果。
状态码可以让我们了解到服务器是正常执行结果,还是出现了错误。
备注:状态码数量很多,不需要去特别记忆,用到时搜索即可。
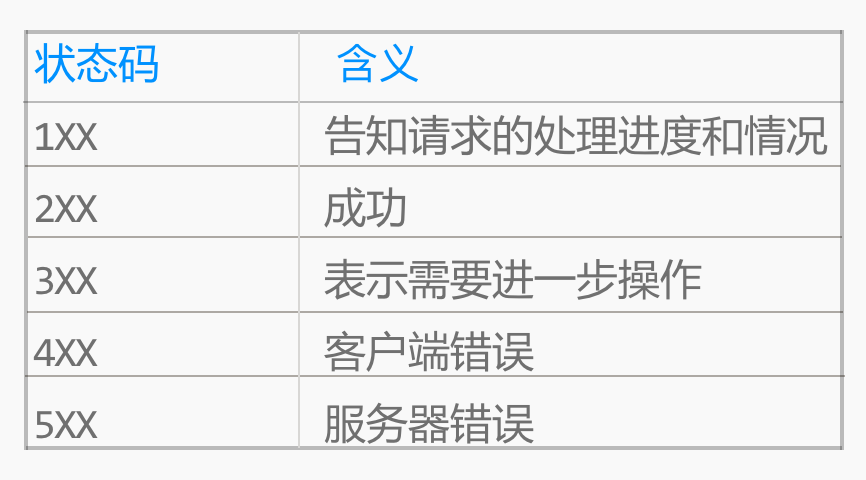
例如:
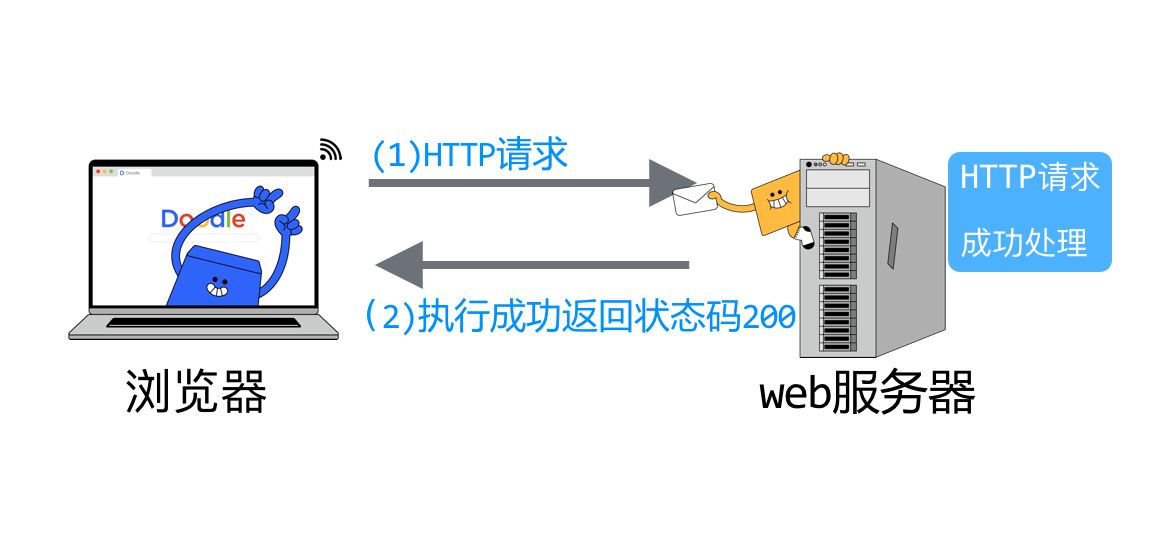
当浏览器发送HTTP请求后,Web服务器执行了请求后。
返回的响应头(Response Headers)中状态码为200,表示执行成功,浏览器此次的请求正常执行。
日常访问网页时,也会遇见状态码:404。
404(Not Found)表示服务器无法找到请求的资源,或者,有的服务器拒绝你的请求并不想说明理由时也会提示404。

或者,有时候打开网页时会提示状态码503。
状态码503(Service Unavailable)表示服务器处于超负荷状态或正在进行停机维护,现在无法处理浏览器的请求。

6.爬虫注意事项
爬虫能够帮助我们自动化的获取网页信息,但是,网络资源也会带来很多问题。
影响服务器性能,爬虫主要请求服务器的资源,大量快速的访问服务器,会影响服务器速度,耗费服务器性能。
法律风险,图片、视频或摄影作品等大部分是有版权的,将抓取的内容商业化也可能带来风险。
网络资源虽然非常丰富,但我们在使用爬虫获取网络资源时,需要遵循网络的基本规则–robots协议。
这个协议一方面是一个爬虫技术人员需要遵守的道德准则。
另一方面,如果将爬取结果商用并获取利益,还会面临法律风险。